Översikt över de olika typerna av personligt identifierbar information som Data & More-klassificeringen automatiskt identifierar
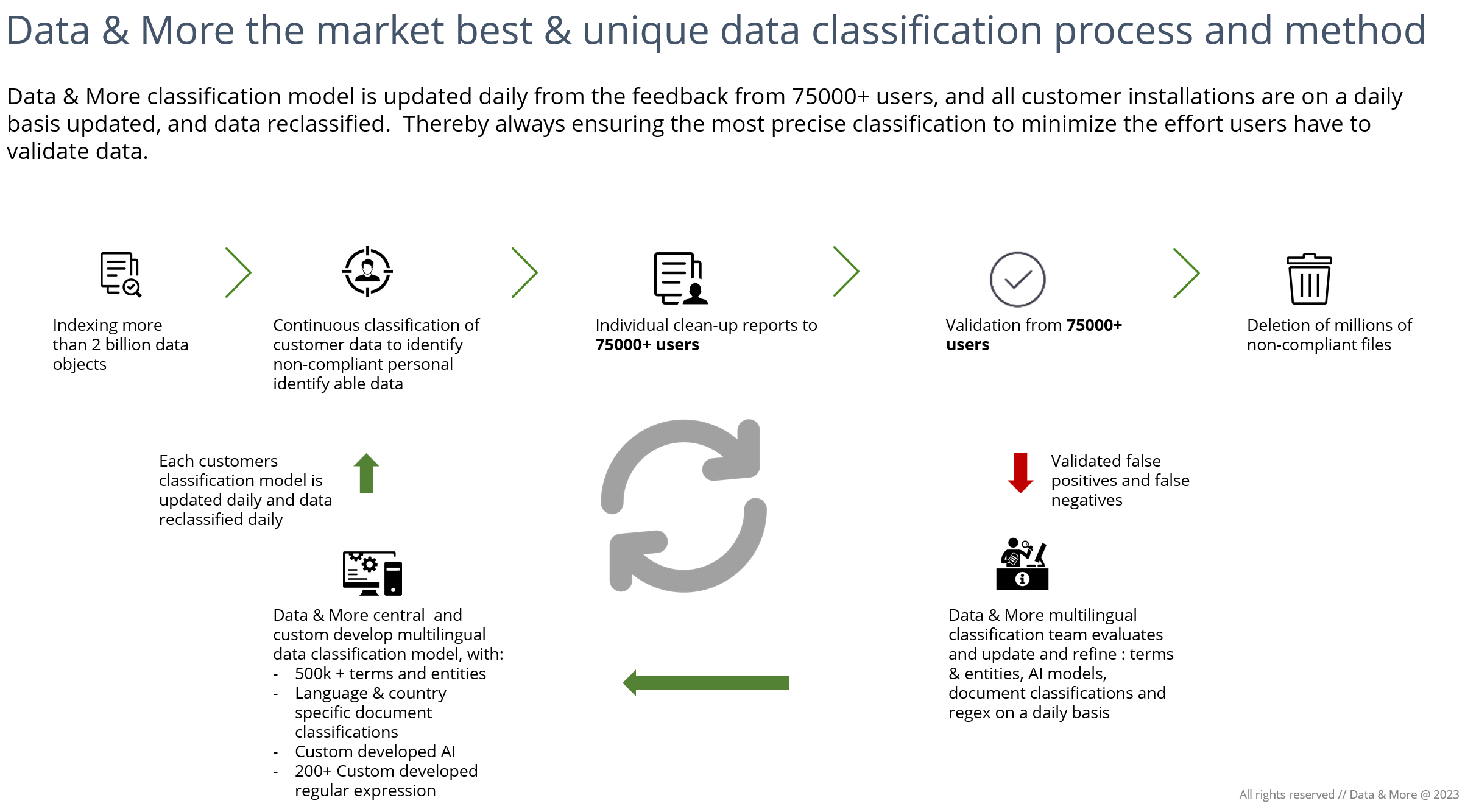
Data & More-lösningen är byggd från grunden för att på ett så precist sätt som möjligt kunna identifiera och klassificera data, och för att sedan på ett effektivt sätt kunna presentera detta för medarbetare så att de kan avgöra om data kan raderas eller lagras. Därefter raderas data över alla källor. Data & More-lösningar bygger på en djup förståelse för språk samt lokala skillnader i språk, landsspecifika enheter och regelverk. En av de viktigaste fördelarna med Data & More-lösningen är att modellen byggs upp och kontinuerligt förbättras, samt att nya klassificeringar dynamiskt läggs till baserat på användarinput och regelverksinput.
Data & More har ett dedikerat klassificeringsteam som uppdaterar ordlistor och klassificeringar på flera språk samt optimerar klassificeringen med hjälp av svar från över 75 000 medarbetare. Data & More använder sig av mycket avancerade, skräddarsydda lösningar: avancerade regler med flera motregler, egenutvecklad AI, anpassade booleska frågor, anpassade undantag, OCR och anpassad bild-AI för att precist kunna identifiera personligt identifierbar information.
Data & More har byggt ordlistor och frasbibliotek med över 500 000 objekt på 25 språk samt lagt till dokumentklassificeringar på flera språk. Allt detta skulle behöva skapas och underhållas av kunden. Vi har aldrig sett det lyckas. Flera har försökt utan framgång.
Data & More klassificerar de olika typerna av personligt identifierbar information i dokumentklasser. Nedan följer en översikt över dokumentklasserna på hög nivå. Var och en av dessa dokumentklasser är uppbyggda av ett stort antal olika underdokumentklasser med mer specifika klassificeringar, t.ex. består Data & More:s dokumentklassificering för Nationellt ID av individuella klassificeringar för de olika nationella ID-handlingar som finns. Som exempel har Data & More mer än 25+ olika metoder för att precist kunna identifiera ett danskt CPR-nummer (det danska nationella ID-numret), och för det tyska passet har vi 5+ olika metoder osv.
Data & More har en unik och dynamisk klassificeringsmodell som uppdateras dagligen baserat på användaråterkoppling avseende falska negativa och falska positiva resultat. Vår centrala dataklassificeringsmodell uppdateras dagligen och alla kunders lösningar uppdateras likaså nattligen, varpå all data omklassificeras med de nya förbättringarna för att säkerställa att slutanvändarna har tillgång till den bästa möjliga och mest korrekta klassificeringen. För de flesta andra klassificeringsmotorer är detta en process som kan ta upp till flera månader.
Översikt över Data & More:s dynamiska återkopplingsloop:
Här är en översikt över alla de olika dokumenttyperna på hög nivå:

Här är en översikt över alla de olika dokumenttyperna på hög nivå med relevanta GDPR-artiklar

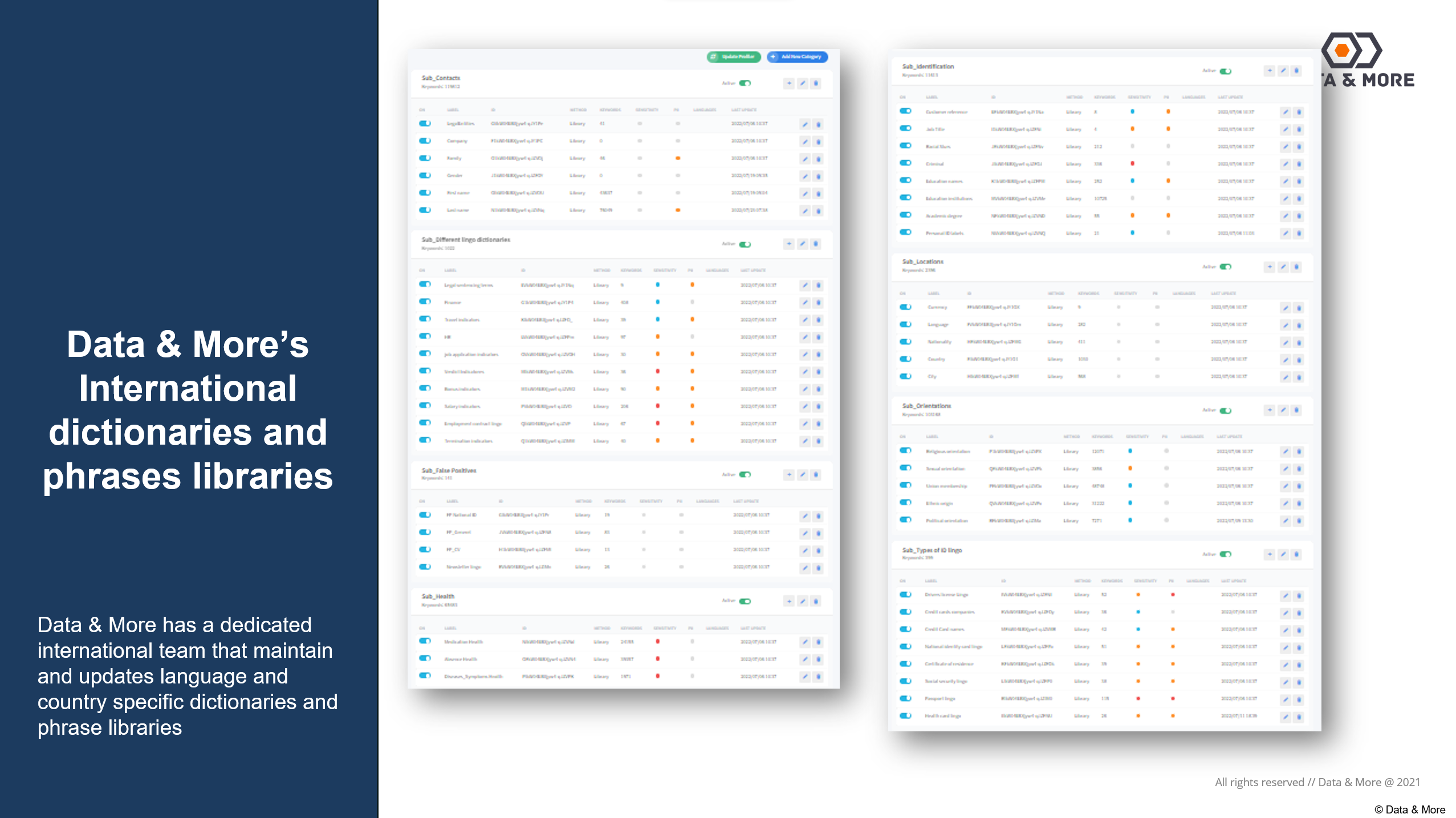
Skärmdump av några av Data & More:s mer än 500 000 entiteter, namn och specifika fraser som underhålls av vårt klassificeringsteam:
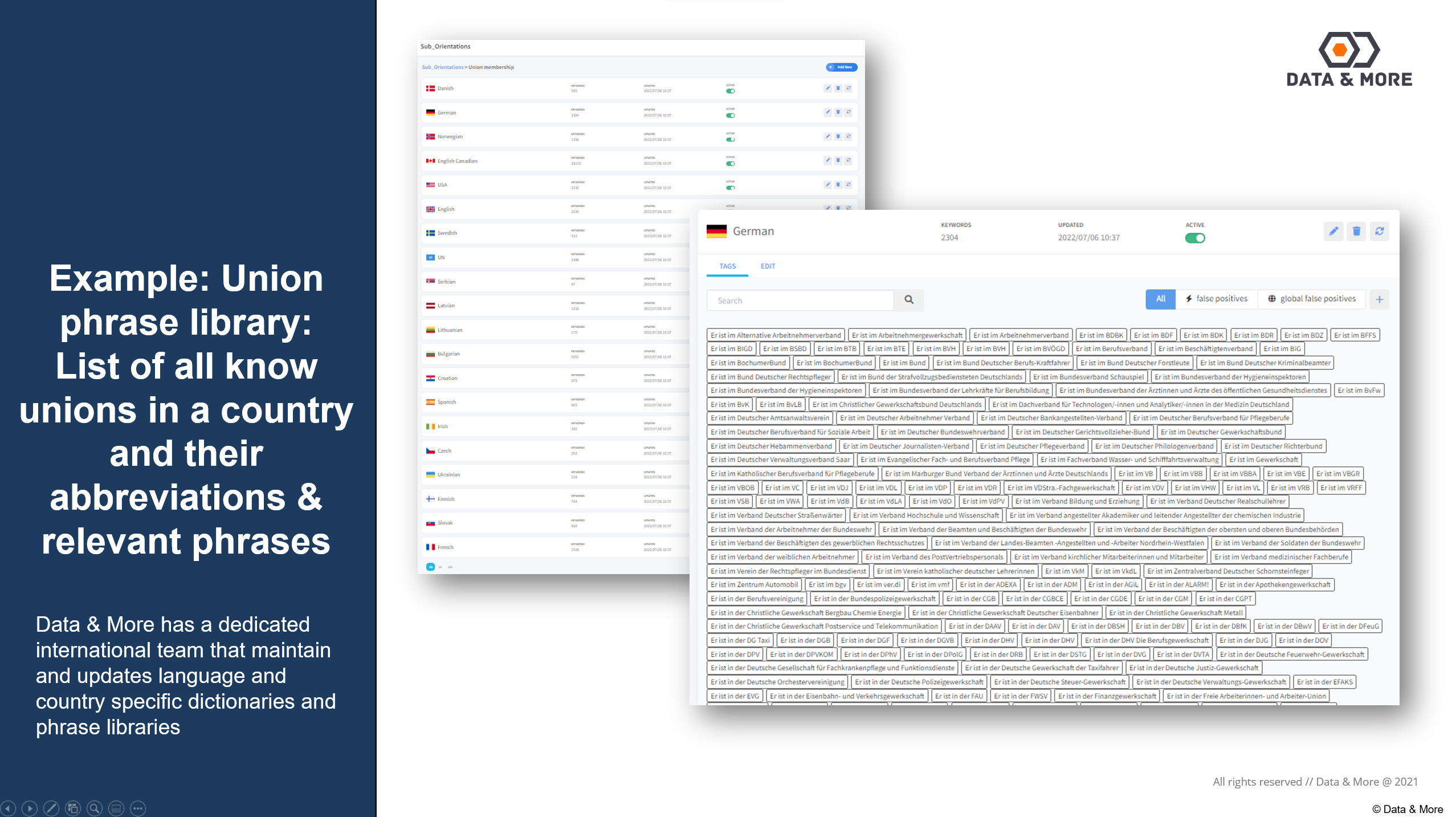
Exempel: Frasbibliotek för fackföreningar: Lista över alla kända fackföreningar i ett land samt deras förkortningar och relevanta fraser
Ytterligare klassificeringsartiklar: