Oversigt over de forskellige typer personhenførbare data, som Data & More-klassificeringen automatisk identificerer
Data & More-løsningen er bygget fra grunden med henblik på at kunne identificere og klassificere data så præcist som muligt og derefter effektivt præsentere disse for medarbejderne, så de kan afgøre, om data kan slettes eller opbevares. Herefter slettes data på tværs af kilder. Data & More-løsningerne er bygget på en dyb forståelse af sprog, lokale sproglige forskelle samt landespecifikke enheder og regulering. En af de vigtigste fordele ved Data & More-løsningen er, at modellen løbende opbygges og forbedres, og at nye klassificeringer dynamisk tilføjes på baggrund af brugerinput og regulatorisk input.
Data & More råder over et dedikeret klassificeringsteam, der opdaterer ordbøger og klassificeringer på adskillige sprog og optimerer klassificeringen på baggrund af svar fra over 75.000 medarbejdere. Data & More anvender meget avancerede og skræddersyede løsninger: avancerede regler med multiple modregler, specialudviklet AI, tilpassede booleske forespørgsler, brugerdefinerede ekskluderinger, OCR samt tilpasset billed-AI til præcis identifikation af personhenførbare data.
Data & More har opbygget ordbøger og sætningsbiblioteker med over 500.000 objekter på 25 sprog og har tilføjet dokumentklassificeringer på adskillige sprog. Alt dette skulle ellers udarbejdes og vedligeholdes af kunden selv. Vi har aldrig set det lykkes. Flere har forsøgt uden succes.
Data & More klassificerer de forskellige typer personhenførbare data i dokumentklasser. Herunder finder De en oversigt over dokumentklasserne på højt niveau. Hver af disse dokumentklasser er opbygget af en række forskellige underdokumentklasser med mere specifikke klassificeringer, f.eks. består Data & More-dokumentklassificeringen for Nationalt ID af individuelle klassificeringer for de forskellige nationale ID-typer, der eksisterer. Som eksempel har Data & More mere end 25+ forskellige metoder til præcis identifikation af et dansk CPR-nummer (Det danske nationale ID-nummer), og for det tyske pas har vi 5+ forskellige metoder osv.
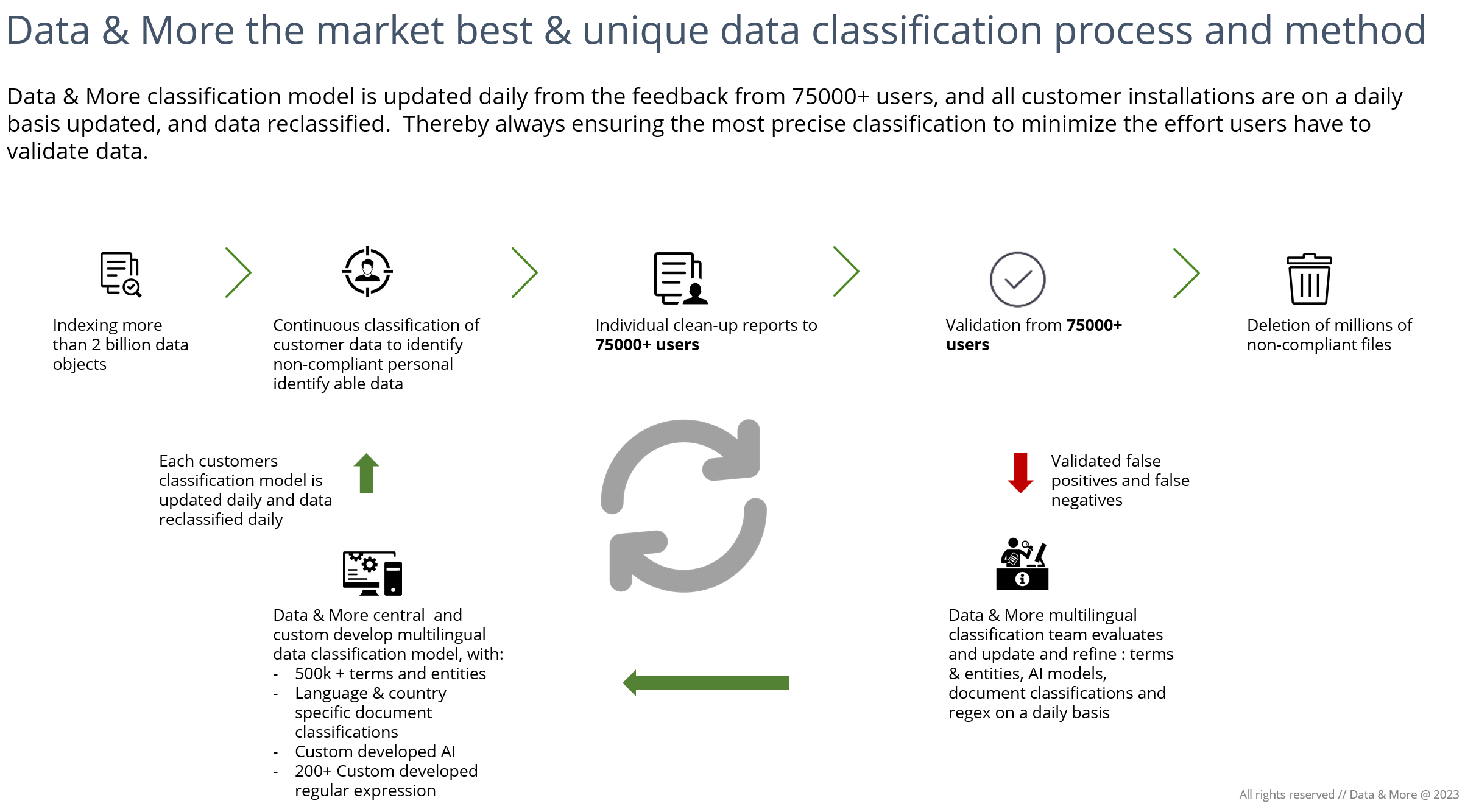
Data & More har en unik og dynamisk klassificeringsmodel, der opdateres dagligt på baggrund af brugerfeedback om falske negative og falske positive resultater. Vores centrale dataklassificeringsmodel opdateres dagligt, og alle kundeløsninger opdateres ligeledes om natten, og alle data genklassificeres med de nye forbedringer for at sikre, at slutbrugerne altid har den bedst mulige og mest præcise klassificering. For de fleste andre klassificeringsmotorer er dette en proces, der kan tage op til adskillige måneder.
Oversigt over Data & More's dynamiske feedbackloop:
Herunder finder De en oversigt over alle de forskellige dokumenttyper på højt niveau:

Herunder finder De en oversigt over alle de forskellige dokumenttyper på højt niveau med de relevante GDPR-artikler

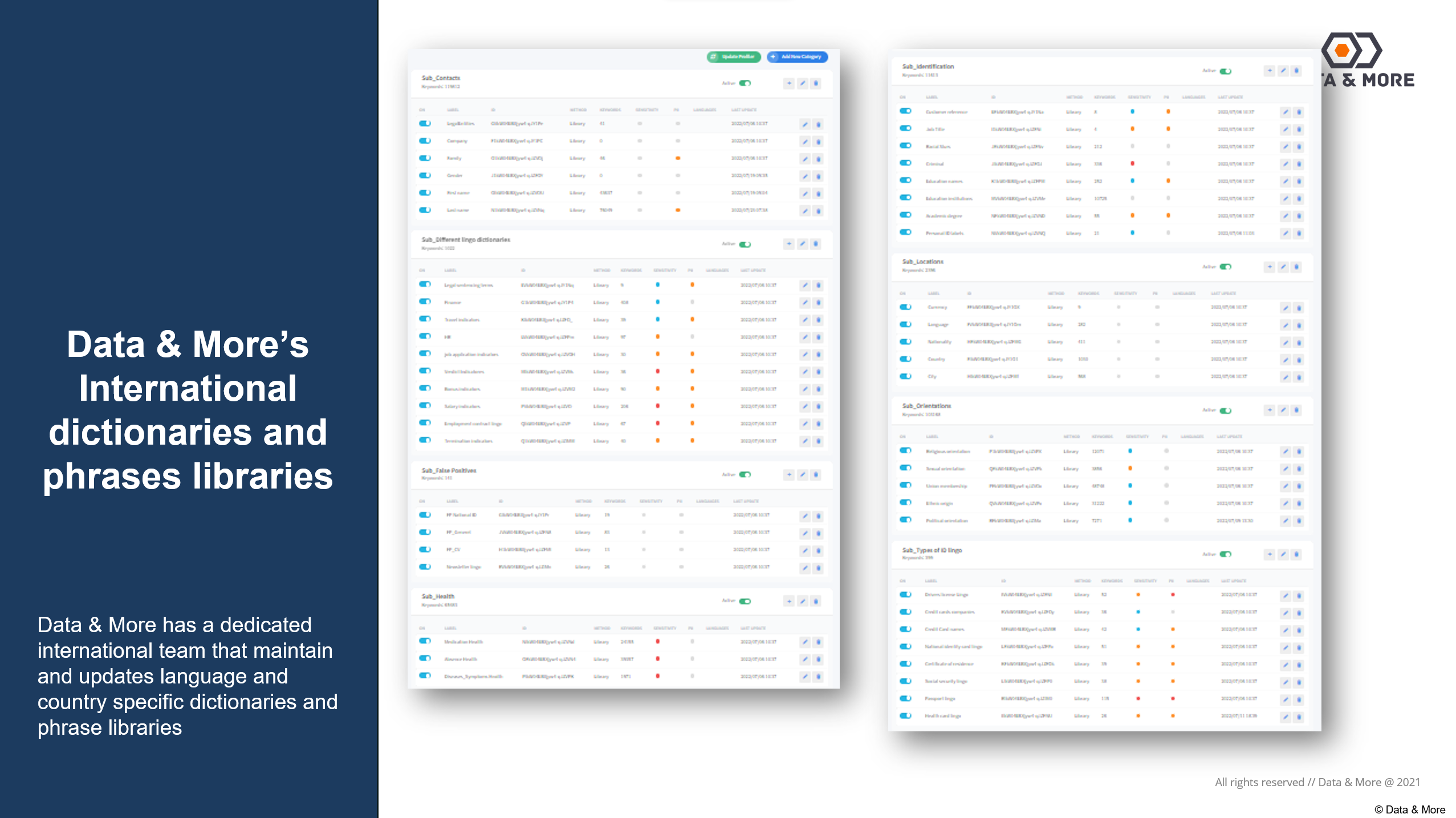
Skærmbillede af nogle af Data & More's mere end 500.000 enheder, navne og specifikke fraser, der vedligeholdes af vores klassificeringsteam:
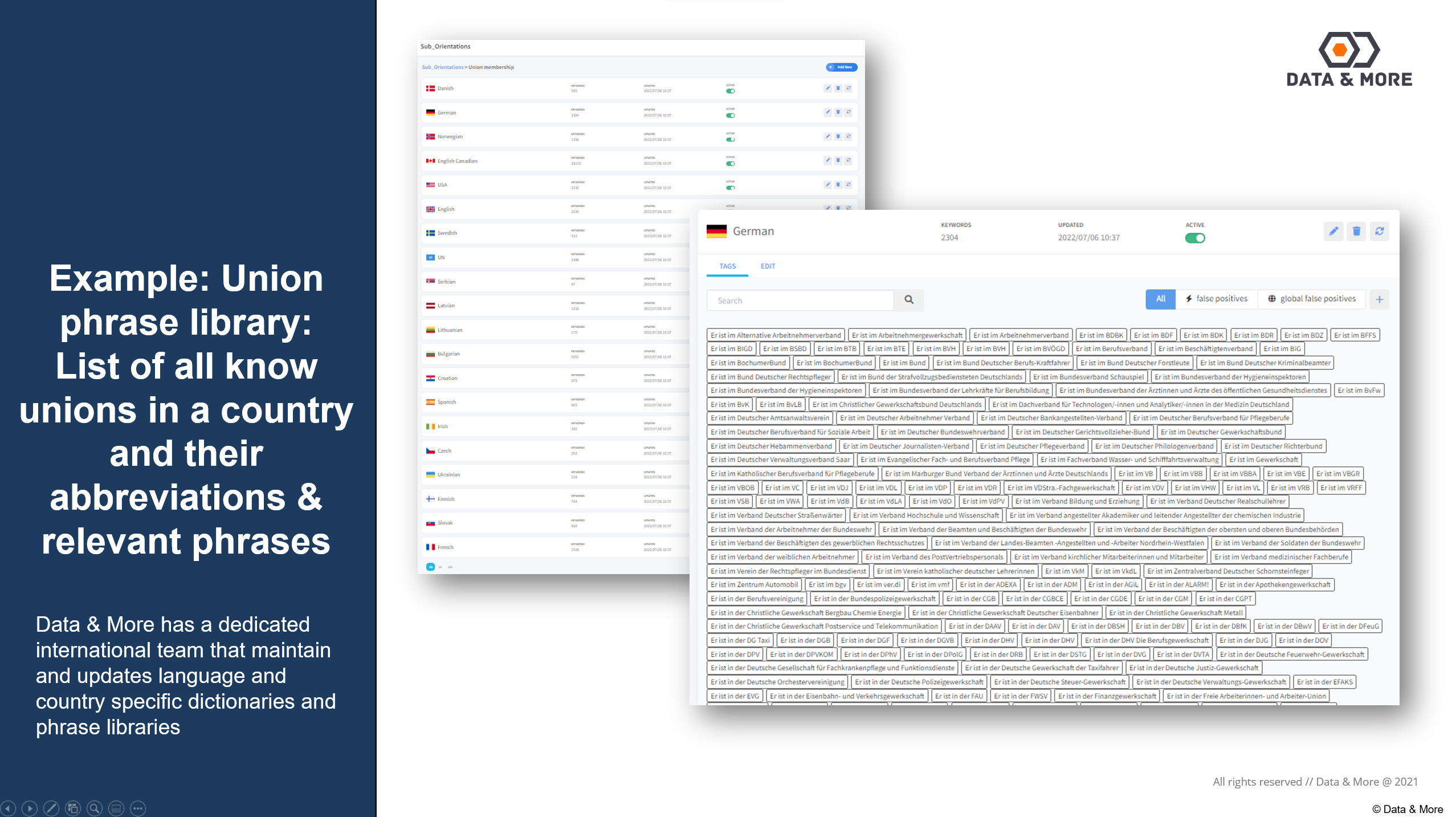
Eksempel: Fagforeningsfrasebibilotek: Liste over alle kendte fagforeninger i et land og deres forkortelser og relevante fraser
Yderligere klassificeringsartikler: