Übersicht über die verschiedenen Arten personenbezogener Daten, die die Data & More Klassifizierung automatisch erkennt
Die Data & More Lösung wurde von Grund auf so entwickelt, dass sie Daten möglichst präzise identifizieren und klassifizieren kann, um diese anschließend den Mitarbeitern effektiv anzuzeigen, damit diese entscheiden können, ob Daten gelöscht oder gespeichert werden sollen. Im nächsten Schritt werden die Daten quellenübergreifend gelöscht. Die Data & More Lösungen basieren auf einem tiefgreifenden Verständnis von Sprache sowie den lokalen sprachlichen Unterschieden und länderspezifischen Entitäten und Vorschriften. Einer der wesentlichen Vorteile der Data & More Lösung besteht darin, dass das Modell kontinuierlich aufgebaut und verbessert wird sowie dynamisch neue Klassifizierungen auf Basis von Nutzer- und Regulierungseingaben hinzufügt.
Data & More verfügt über ein eigenes Klassifizierungsteam, das Wörterbücher und Klassifizierungen in mehreren Sprachen aktualisiert und die Klassifizierung anhand von Antworten aus über 75.000 Mitarbeiterbefragungen optimiert. Data & More setzt hochentwickelte, maßgeschneiderte Technologien ein: erweiterte Regeln mit mehreren Gegenregeln, individuell entwickelte KI, benutzerdefinierte Boolean-Abfragen, benutzerdefinierte Ausschlüsse, OCR sowie eine benutzerdefinierte Bild-KI, um personenbezogene Daten präzise identifizieren zu können.
Data & More hat Wörterbücher und Phrasensammlungen mit über 500.000 Objekten in 25 Sprachen aufgebaut und Dokumentklassifizierungen in mehreren Sprachen hinzugefügt. All dies müsste vom Kunden selbst erstellt und gepflegt werden. Wir haben noch nie erlebt, dass dies erfolgreich umgesetzt wurde. Mehrere Versuche sind daran gescheitert.
Data & More klassifiziert die verschiedenen Arten personenbezogener Daten in Dokumentklassen. Nachfolgend finden Sie eine Übersicht der übergeordneten Dokumentklassen. Jede dieser Dokumentklassen setzt sich aus einer Vielzahl verschiedener Unterdokumentklassen mit spezifischeren Klassifizierungen zusammen. So besteht beispielsweise die Data & More Dokumentklassifizierung für Nationale Ausweisdokumente aus individuellen Klassifizierungen für die verschiedenen nationalen Ausweisdokumente, die existieren. Als Beispiel sei genannt, dass Data & More über mehr als 25 verschiedene Methoden verfügt, um eine dänische CPR-Nummer (die dänische nationale Personalausweisnummer) präzise zu identifizieren, für den deutschen Reisepass stehen 5+ verschiedene Methoden zur Verfügung usw.
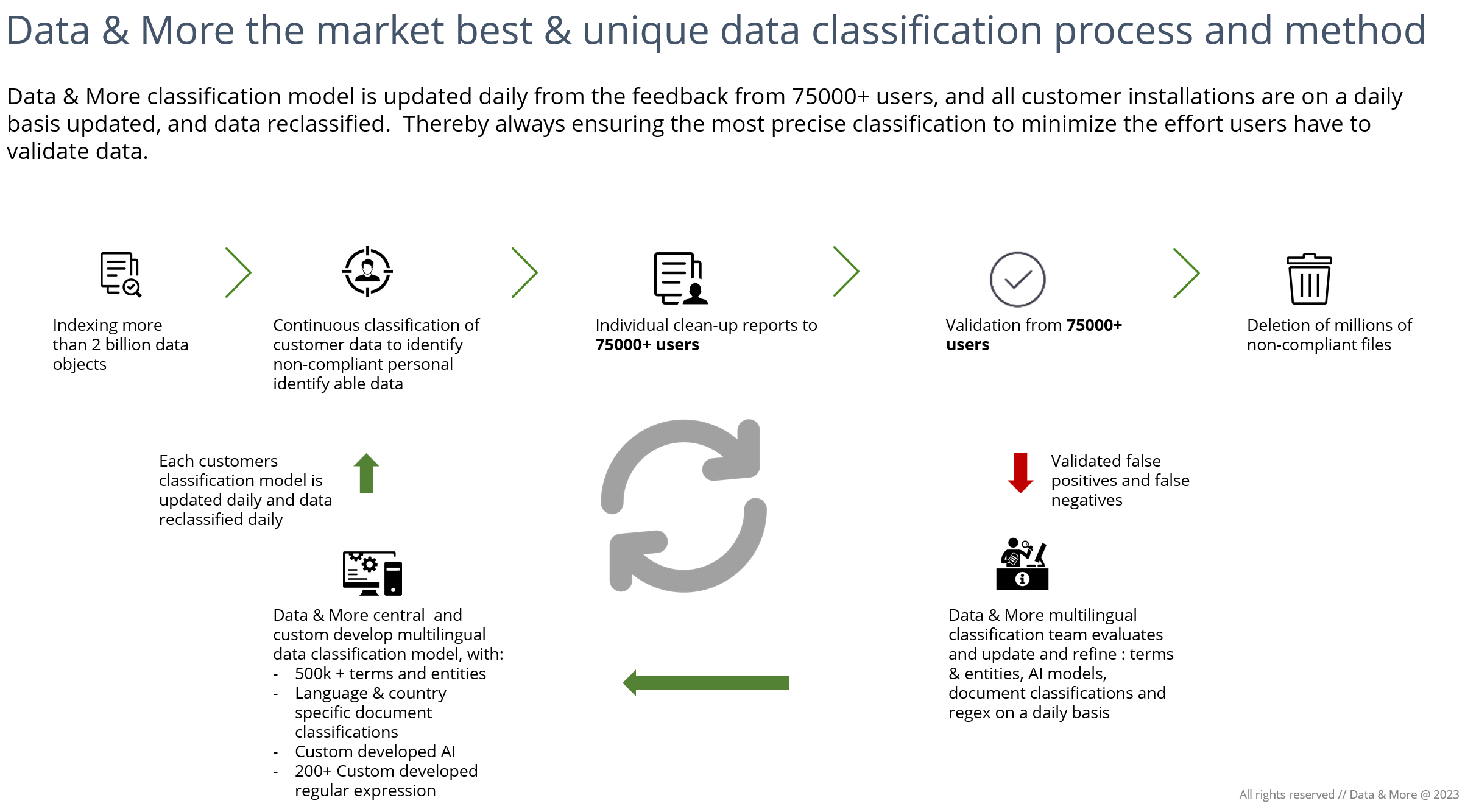
Data & More verfügt über ein einzigartiges und dynamisches Klassifizierungsmodell, das täglich auf Basis von Nutzerfeedback zu falsch negativen und falsch positiven Ergebnissen aktualisiert wird. Unser zentrales Datenklassifizierungsmodell wird täglich aktualisiert, und alle Kundenlösungen werden ebenfalls nächtlich aktualisiert. Alle Daten werden mit den neuen Verbesserungen neu klassifiziert, um sicherzustellen, dass den Endnutzern die bestmögliche und genaueste Klassifizierung zur Verfügung steht. Bei den meisten anderen Klassifizierungs-Engines ist dies ein Prozess, der bis zu mehrere Monate in Anspruch nehmen kann.
Übersicht über den dynamischen Feedback-Kreislauf von Data & More:
Hier finden Sie eine Übersicht aller verschiedenen übergeordneten Dokumenttypen:

Hier finden Sie eine Übersicht aller verschiedenen übergeordneten Dokumenttypen mit den relevanten DSGVO-Artikeln

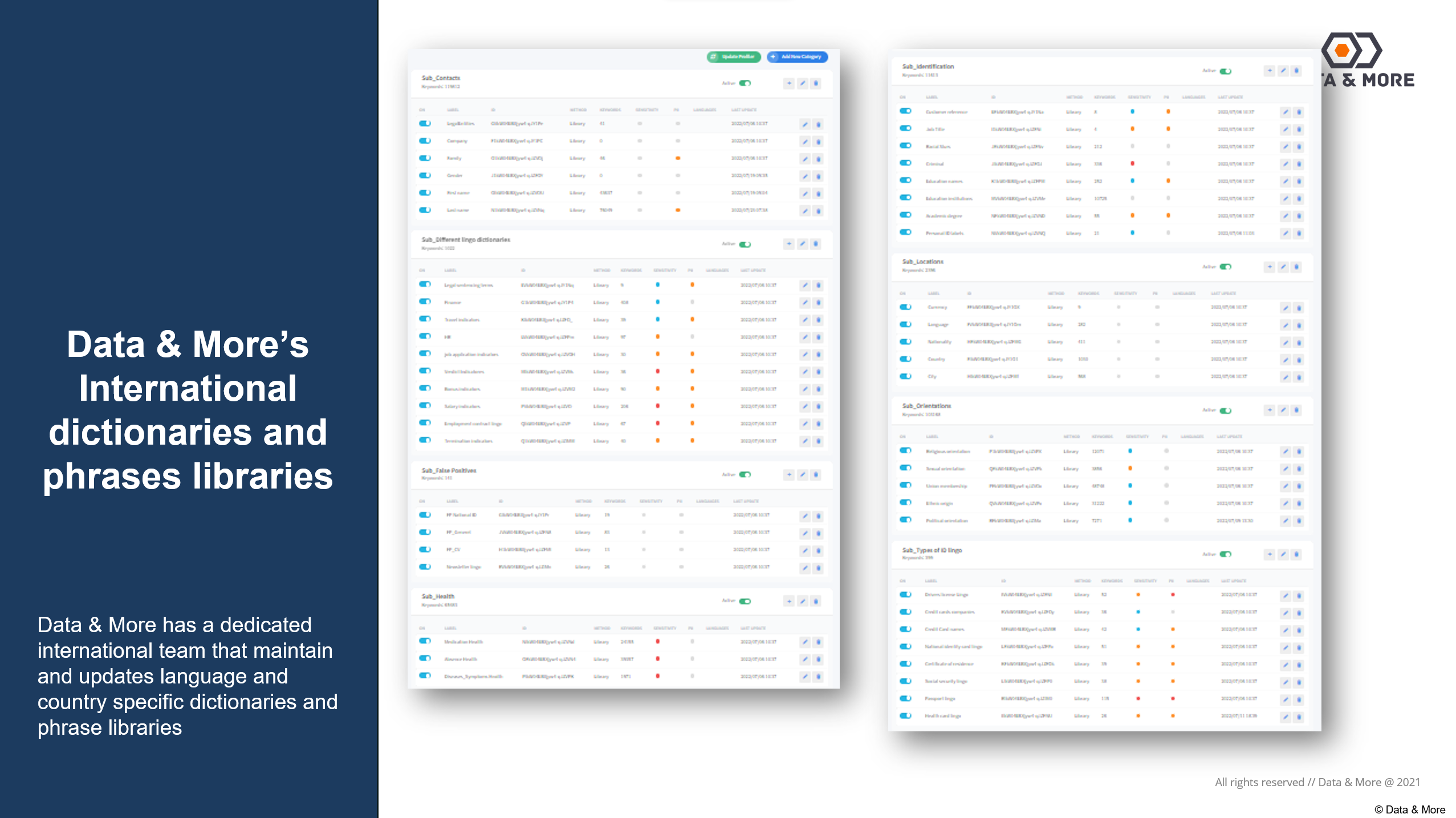
Screenshot einiger der über 500.000 Entitäten, Namen und spezifischen Phrasen, die von unserem Klassifizierungsteam gepflegt werden:
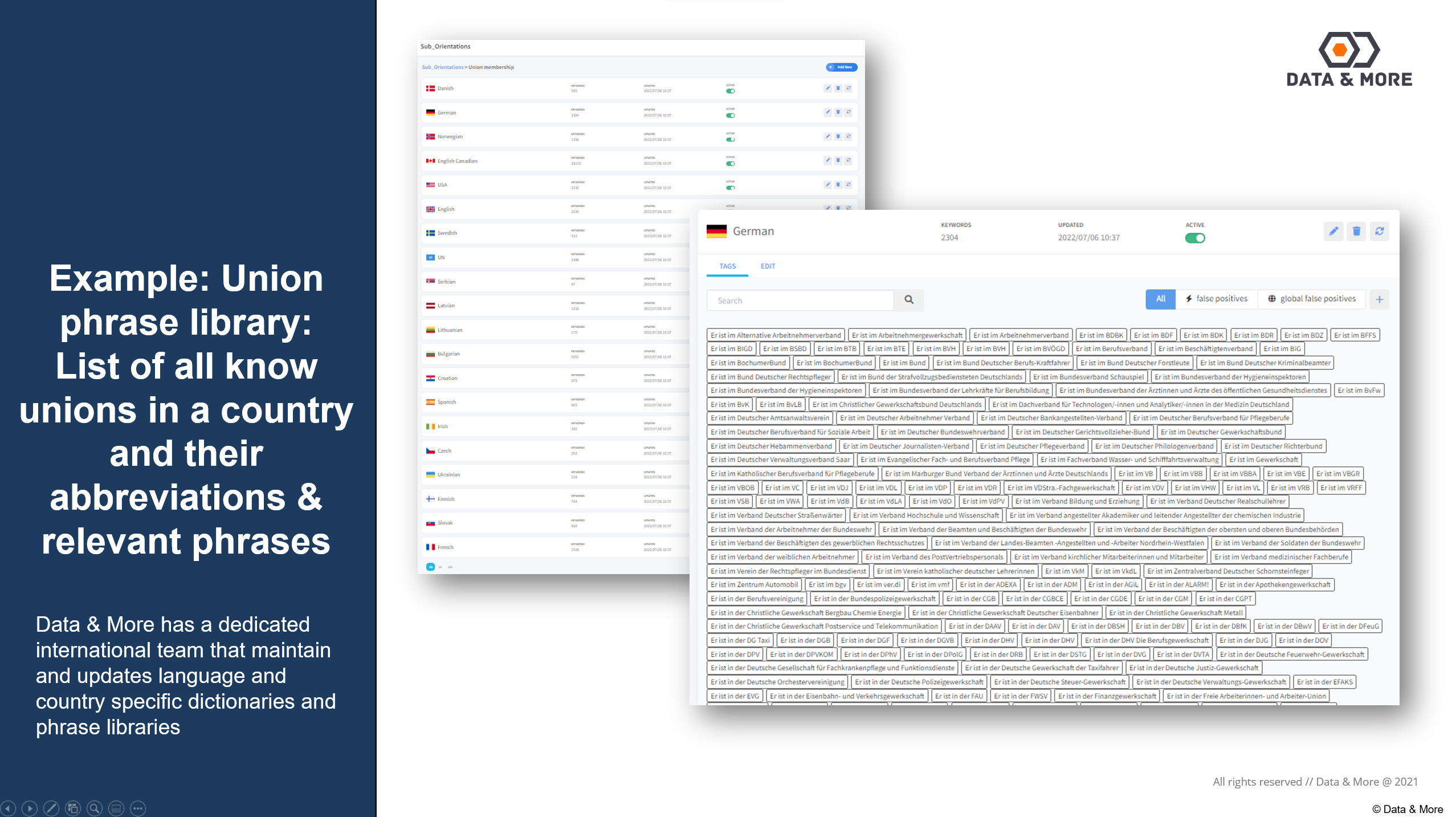
Beispiel: Gewerkschafts-Phrasensammlung:Liste aller bekannten Gewerkschaften in einem Land sowie deren Abkürzungen und relevante Phrasen
Weitere Artikel zur Klassifizierung: